

知识蒸馏
基础简介
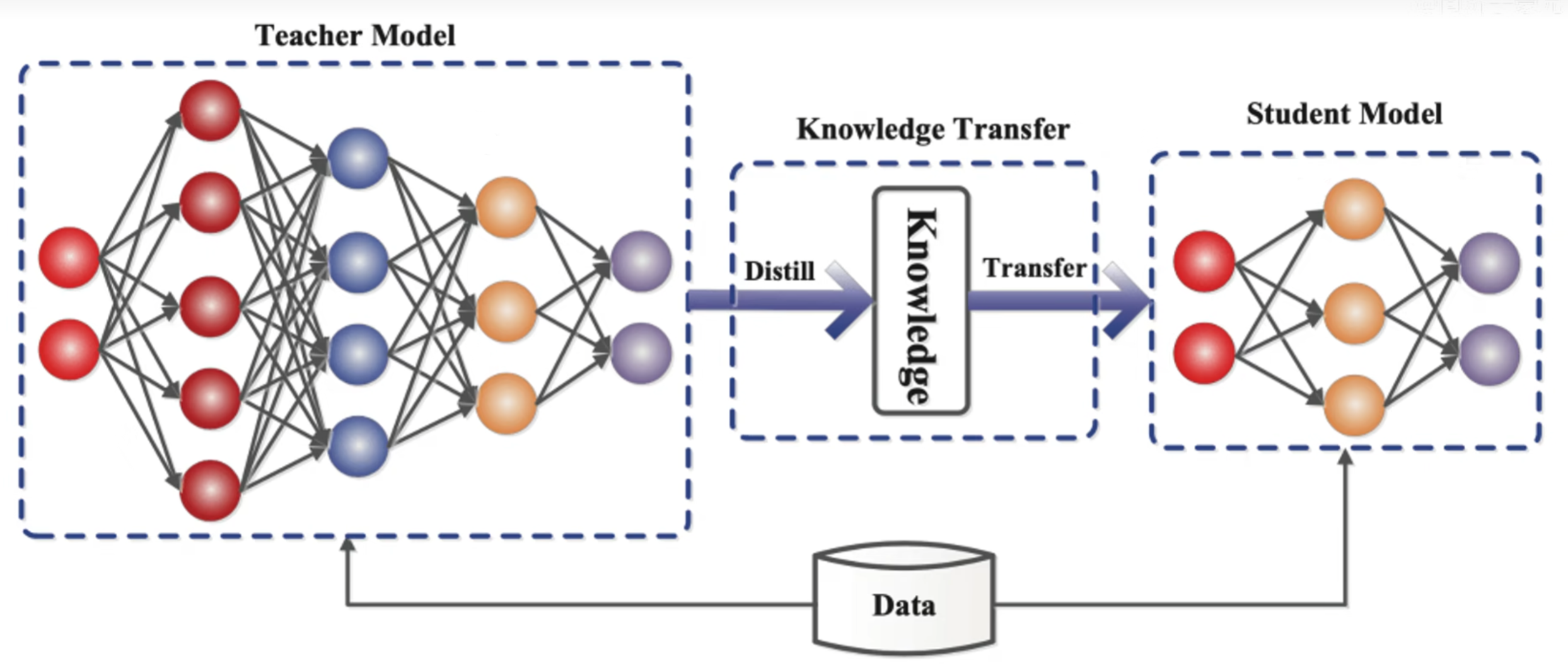
知识蒸馏就是把一个大的教师模型的知识萃取出来,把他浓缩到一个小的学生模型,可以理解为一个大的教师神经网络把他的知识教给小的学生网络,这里有一个知识的迁移过程,从教师网络迁移到了学生网络身上,教师网络一般是比较臃肿,所以教师网络把知识教给学生网络,学生网络是一个比较小的网络,这样就可以用学生网络去做一些轻量化网络做的事情。
这样做的目的是在尽可能保留教师模型的性能的同时,使学生模型在资源使用上更加高效,尤其是在计算和存储方面。
具体步骤
1、教师模型训练
先训练一个大而复杂的教师模型,使其在目标任务上具有较高的性能。
2、生成软标签
教师模型不仅仅给出最终预测的类别标签(硬标签),而是提供更丰富的信息,这通常是 软标签(Soft Targets)。软标签是指通过教师模型的输出概率分布,包含了关于类别间相对关系的更多信息。比如,教师模型可能会预测某个样本属于某一类别的概率为 0.8,而属于另一个类别的概率为 0.1,这些信息对学生模型非常有用。
这些软标签包含了更多的信息,例如类间的相似度或类别之间的竞争关系,相比于单一的硬标签(0 或 1),它们提供了更丰富的语义信息。
3、学生模型训练
学生模型不仅仅通过传统的监督学习来拟合训练数据的硬标签,还要通过模仿教师模型的行为来学习软标签。通常,学生模型的目标是最小化其预测与教师模型预测(软标签)之间的差异
4、损失函数
在知识蒸馏中,损失函数通常由两部分组成:
传统的分类损失:通过真实的硬标签来训练学生模型,这部分类似于常规的监督学习。
蒸馏损失:通过最小化学生模型输出与教师模型输出之间的差异(通常是使用KL散度或交叉熵)来训练学生模型。这部分引导学生模型学习教师模型的“软”知识。
硬标签损失(Hard Labels Loss):这部分是标准的分类损失,用于监督学生模型准确地预测真实的类别标签。
软标签损失(Soft Labels Loss):通过将学生模型的输出概率分布与教师模型的输出概率分布进行对比,常常使用 Kullback-Leibler (KL) 散度 来衡量两者的相似度。通过这部分损失,学生模型能够学习教师模型在不同类别间的“软”预测概率。
优势与挑战
优势:
模型压缩:通过知识蒸馏,学生模型通常可以拥有比教师模型小得多的参数量,而仍能保持较好的性能。
提高泛化能力:学生模型不仅通过训练数据学习,也能从教师模型的知识中汲取更多的通用特征,从而提升其泛化能力。
加速推理:学生模型由于较小,计算和存储开销相对较低,能够更快速地进行推理,特别适用于资源受限的环境(如移动设备、嵌入式系统等)。
挑战:
选择合适的教师模型:教师模型的性能和复杂度直接影响蒸馏效果。如果教师模型的性能较差,蒸馏出来的学生模型也可能无法达到理想的效果。
平衡蒸馏和硬标签损失:在设计损失函数时,如何选择合适的权重来平衡硬标签损失和软标签损失是一个挑战。过度依赖软标签可能导致学生模型失去对训练数据的准确建模。
为什么能减小模型大小?
核心原因:学生模型不再需要保留教师模型中所有的参数、层次和复杂的计算过程,而是通过蒸馏过程将 教师模型的决策模式和概率信息 转化为更加高效的特征表示。学生模型可以减少冗余的计算,同时保留对任务有效的特征和抽象的决策能力。
输出的转化:学生模型通过模仿教师模型输出的概率分布(软标签),并不依赖于每一个复杂的计算步骤或中间层表示。通过这种方式,学生模型能以更小的规模 捕捉到任务的核心决策信息,并且仍能在推理时得到相对准确的结果。
代码
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F
from torch.utils.data import DataLoader, TensorDataset
# 假设我们有一些随机数据来做演示
# 用随机数据创建一个简单的DataLoader
X_train = torch.randn(1000, 784) # 1000 个样本,每个样本 784 特征 (例如 28x28 图像)
y_train = torch.randint(0, 10, (1000,)) # 10 个类别
train_dataset = TensorDataset(X_train, y_train)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)
# 定义教师模型 (一个简单的 CNN)
class TeacherModel(nn.Module):
def __init__(self):
super(TeacherModel, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(32 * 14 * 14, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(-1, 1, 28, 28) # 重新调整输入形状为 (batch_size, 1, 28, 28)
x = self.pool(F.relu(self.conv1(x)))
x = x.view(-1, 32 * 14 * 14)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 定义学生模型 (一个较小的 MLP)
class StudentModel(nn.Module):
def __init__(self):
super(StudentModel, self).__init__()
self.fc1 = nn.Linear(784, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 训练教师模型的函数
def train_teacher_model(teacher_model, train_loader, device):
teacher_model.train()
optimizer = optim.Adam(teacher_model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = teacher_model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
# 知识蒸馏的训练函数
def distill(teacher_model, student_model, train_loader, device, alpha=0.5, T=2.0):
student_model.train()
optimizer = optim.Adam(student_model.parameters(), lr=0.001)
criterion = nn.CrossEntropyLoss()
for data, target in train_loader:
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
# 教师模型的输出(软标签)
with torch.no_grad(): # 教师模型不需要反向传播
teacher_output = teacher_model(data)
# 学生模型的输出
student_output = student_model(data)
# 计算蒸馏损失:软标签损失 + 硬标签损失
soft_loss = F.kl_div(
F.log_softmax(student_output / T, dim=1),
F.softmax(teacher_output / T, dim=1),
reduction='batchmean'
) * (T * T)
hard_loss = criterion(student_output, target)
# 总损失
loss = alpha * soft_loss + (1.0 - alpha) * hard_loss
# 反向传播
loss.backward()
optimizer.step()
# 打印当前批次的损失
print(f"Loss: {loss.item()}")
# 设置设备:GPU 或 CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 初始化模型
teacher_model = TeacherModel().to(device)
student_model = StudentModel().to(device)
# 训练教师模型
train_teacher_model(teacher_model, train_loader, device)
# 在训练结束后,使用教师模型进行知识蒸馏训练学生模型
distill(teacher_model, student_model, train_loader, device)